Aggregated Value Stream Analytics
Introduced in GitLab 14.7.
This page provides a high-level overview of the aggregated backend for Value Stream Analytics (VSA).
Current Status
The aggregated backend is used by default since GitLab 15.0 on the group-level.
Motivation
The aggregated backend aims to solve the performance limitations of the VSA feature and set it up for long-term growth.
Our main database is not prepared for analytical workloads. Executing long-running queries can affect the reliability of the application. For large groups, the current implementation (old backend) is slow and, in some cases, doesn’t even load due to the configured statement timeout (15 s).
The database queries in the old backend use the core domain models directly through
IssuableFinders classes: (MergeRequestsFinder and IssuesFinder).
With the requested change of the date range filters,
this approach was no longer viable from the performance point of view.
Benefits of the aggregated VSA backend:
- Simpler database queries (fewer JOINs).
- Faster aggregations, only a single table is accessed.
- Possibility to introduce further aggregations for improving the first page load time.
- Better performance for large groups (with many subgroups, projects, issues and, merge requests).
- Ready for database decomposition. The VSA related database tables could live in a separate database with a minimal development effort.
- Ready for keyset pagination which can be useful for exporting the data.
- Possibility to implement more complex event definitions.
- For example, the start event can be two timestamp columns where the earliest value would be used by the system.
- Example:
MIN(issues.created_at, issues.updated_at)
Example configuration
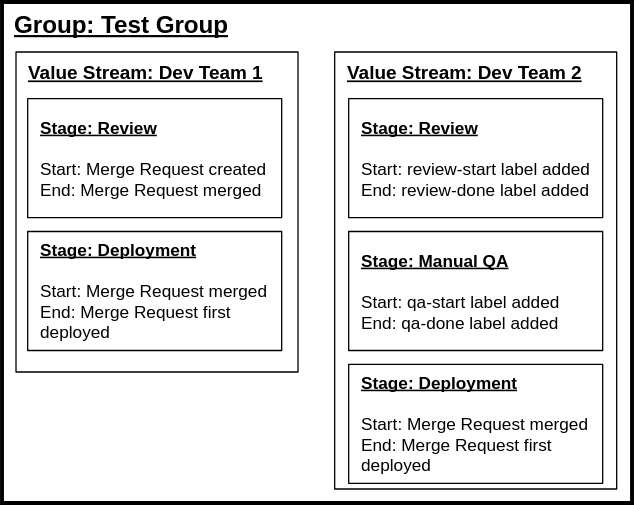
In this example, two independent value streams are set up for two teams that are using
different development workflows within the Test Group (top-level namespace).
The first value stream uses standard timestamp-based events for defining the stages. The second value stream uses label events.
Each value stream and stage item from the example is persisted in the database. Notice that
the Deployment stage is identical for both value streams; that means that the underlying
stage_event_hash_id is the same for both stages. The stage_event_hash_id reduces
the amount of data the backend collects and plays a vital role in database partitioning.
We expect value streams and stages to be rarely changed. When stages (start and end events) are changed, the aggregated data gets stale. This is fixed by the periodical aggregation occurring every day.
Feature availability
The aggregated VSA feature is available on the group and project level however, the aggregated backend is only available for Premium and Ultimate customers due to data storage and data computation costs. Storing de-normalized, aggregated data requires significant disk space.
Aggregated value stream analytics architecture
The main idea behind the aggregated VSA backend is separation: VSA database tables and queries do not use the core domain models directly (Issue, MergeRequest). This allows us to scale and optimize VSA independently from the other parts of the application.
The architecture consists of two main mechanisms:
- Periodical data collection and loading (happens in the background).
- Querying the collected data (invoked by the user).
Data loading
The aggregated nature of VSA comes from the periodical data loading. The system queries the core domain models to collect the stage and timestamp data. This data is periodically inserted into the VSA database tables.
High-level overview for each top-level namespace with Premium or Ultimate license:
- Load all stages in the group.
- Iterate over the issues and merge requests records.
- Based on the stage configurations (start and end event identifiers) collect the timestamp data.
-
INSERTorUPDATEthe data into the VSA database tables.
The data loading is implemented within the Analytics::CycleAnalytics::DataLoaderService
class. Some groups contain a lot of data, so to avoid overloading the primary database,
the service performs operations in batches and enforces strict application limits:
- Load records in batches.
- Insert records in batches.
- Stop processing when a limit is reached, schedule a background job to continue the processing later.
- Continue processing data from a specific point.
As of GitLab 14.7, the data loading is done manually. Once the feature is ready, the service is invoked periodically by the system via a cron job (this part is not implemented yet).
Record iteration
The batched iteration is implemented with the
efficient IN operator. The background job scans
all issues and merge request records in the group hierarchy ordered by the updated_at and the
id columns. For already aggregated groups, the DataLoaderService continues the aggregation
from a specific point which saves time.
Collecting the timestamp data happens on every iteration. The DataLoaderService determines which
stage events are configured within the group hierarchy and builds a query that selects the
required timestamps. The stage record knows which events are configured and the events know how to
select the timestamp columns.
Example for collected stage events: merge request merged, merge request created, merge request closed
Generated SQL query for loading the timestamps:
SELECT
-- the list of columns depends on the configured stages
"merge_request_metrics"."merged_at",
"merge_requests"."created_at",
"merge_request_metrics"."latest_closed_at"
FROM "merge_requests"
LEFT OUTER JOIN "merge_request_metrics" ON "merge_request_metrics"."merge_request_id" = "merge_requests"."id"
WHERE "merge_requests"."id" IN (1, 2, 3, 4) -- ids are coming from the batching query
The merged_at column is located in a separate table (merge_request_metrics). The
Gitlab::Analytics::CycleAnalytics::StagEvents::MergeRequestMerged class adds itself to a scope
for loading the timestamp data without affecting the number of rows (uses LEFT JOIN). This
behavior is implemented for each StageEvent class with the include_in method.
The data collection query works on the event level. It extracts the event timestamps from the stages and ensures that we don’t collect the same data multiple times. The events mentioned above could come from the following stage configuration:
- merge request created - merge request merged
- merge request created - merge request closed
Other combinations might be also possible, but we prevent the ones that make no sense, for example:
- merge request merged - merge request created
Creation time always happens first, so this stage always reports negative duration.
Data scope
The data collection scans and processes all issues and merge requests records in the group hierarchy, starting from the top-level group. This means that if a group only has one value stream in a subgroup, we nevertheless collect data of all issues and merge requests in the hierarchy of this group. This aims to simplify the data collection mechanism. Moreover, data research shows that most group hierarchies have their stages configured on the top level.
During the data collection process, the collected timestamp data is transformed into rows. For each configured stage, if the start event timestamp is present, the system inserts or updates one event record. This allows us to determine the upper limit of the inserted rows per group by counting all issues and merge requests and multiplying the sum by the stage count.
Data consistency concerns
Due to the async nature of the data collection, data consistency issues are bound to happen. This is a trade-off that makes the query performance significantly faster. We think that for analytical workload a slight lag in the data is acceptable.
Before the rollout we plan to implement some indicators on the VSA page that shows the most recent backend activities. For example, indicators that show the last data collection timestamp and the last consistency check timestamp.
Database structure
VSA collects data for the following domain models: Issue and MergeRequest. To keep the
aggregated data separated, we use two additional database tables:
analytics_cycle_analytics_issue_stage_eventsanalytics_cycle_analytics_merge_request_stage_events
Both tables are hash partitioned by the stage_event_hash_id. Each table uses 32 partitions. It’s
an arbitrary number and it could be changed. Important is to keep the partitions under 100 GB in
size (which gives the feature a lot of headroom).
| Column | Description |
|---|---|
stage_event_hash_id | partitioning key |
merge_request_id or issue_id
| reference to the domain record (Issuable) |
group_id | reference to the group (de-normalization) |
project_id | reference to the project |
milestone_id | duplicated data from the domain record table |
author_id | duplicated data from the domain record table |
state_id | duplicated data from the domain record table |
start_event_timestamp | timestamp derived from the stage configuration |
end_event_timestamp | timestamp derived from the stage configuration |
With accordance to the data separation requirements, the table doesn’t have any foreign keys. The consistency is ensured by a background job (eventually consistent).
Data querying
The base query always includes the following filters:
-
stage_event_hash_id- partition key -
project_idorgroup_id- depending if it’s a project or group level query -
end_event_timestamp- date range filter (last 30 days)
Example: Selecting review stage duration for the GitLab project
SELECT end_event_timestamp - start_event_timestamp
FROM analytics_cycle_analytics_merge_request_stage_events
WHERE
stage_event_hash_id = 16 AND -- hits a specific partition
project_id = 278964 AND
end_event_timestamp > '2022-01-01' AND end_event_timestamp < '2022-01-30'
Query generation
The query backend is hidden behind the same interface that the old backend implementation uses. Thanks to this, we can easily switch between the old and new query backends.
-
DataCollector: entrypoint for querying VSA data-
BaseQueryBuilder: provides the baseActiveRecordscope (filters are applied here). -
average: average aggregation. -
median: median aggregation. -
count: row counting. -
records: list of issue or merge request records.
-
Filters
VSA supports various filters on the base query. Most of the filters require no additional JOINs:
| Filter name | Description |
|---|---|
milestone_title | The backend translates it to milestone_id filter |
author_username | The backend translates it to author_id filter |
project_ids | Only used on the group-level |
Exceptions: these filters are applied on other tables which means we JOIN them.
| Filter name | Description |
|---|---|
label_name | Array filter, using the label_links table |
assignee_username | Array filter, using the *_assignees table |
To fully decompose the database, the required ID values would need to be replicated in the VSA database tables. This change could be implemented using array columns.
Endpoints
The feature uses private JSON APIs for delivering the data to the frontend. On the first page load , the following requests are invoked:
- Initial HTML page load which is mostly empty. Some configuration data is exposed via
dataattributes. -
value_streams- Load the available value streams for the given group. -
stages- Load the stages for the currently selected value stream. -
median- For each stage, request the median duration. -
count- For each stage, request the number of items in the stage (this is a limit count, maximum 1000 rows). -
average_duration_chart- Data for the duration chart. -
summary,time_summary- Top-level aggregations, most of the metrics are using different APIs/ finders and not invoking the aggregated backend.
When selecting a specific stage, the records endpoint is invoked, which returns the related
records (paginated) for the chosen stage in a specific order.
Database decomposition
By separating the query logic from the main application code, the feature is ready for database decomposition. If we decide that VSA requires a separate database instance, then moving the aggregated tables can be accomplished with little effort.
A different database technology could also be used to further improve the performance of the feature, for example Timescale DB.